在多线程环境中,使用HashMap进行put操作时会引起死循环,导致CPU使用接近100%,下面通过代码分析一下为什么会发生死循环。
首先先分析一下HashMap的数据结构:HashMap底层数据结构是有一个链表数据构成的,HashMap中定义了一个静态内部类作为链表,代码如下:
静态内部类entry代码
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
Hashmap属性代码
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
之所以会导致HashMap出现死循环是因为多线程会导致HashMap的Entry节点形成环链,这样当遍历集合时Entry的next节点用于不为空,从而形成死循环
单添加元素时会通过key的hash值确认链表数组下标
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
//确认链表数组位置
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果key相同则覆盖value部分
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//添加链表节点
addEntry(hash, key, value, i);
return null;
}
下面看一下HashMap添加节点的实现
void addEntry(int hash, K key, V value, int bucketIndex) {
//bucketIndex 通过key的hash值与链表数组的长度计算得出
Entry<K,V> e = table[bucketIndex];
//创建链表节点
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//判断是否需要扩容
if (size++ >= threshold)
resize(2 * table.length);
}
以上部分的实现不会导致链路出现环链,环链一般会出现HashMap扩容是,下面看看扩容的实现:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);//可能导致环链
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
下面transfer的实现:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
这个方法的目的是将原链表数据的数组拷到新的链表数组中,拷贝过程中如果形成环链的呢?下面用一个简单的例子来说明一下:
public class InfiniteLoop {
static final Map<Integer, Integer> map = new HashMap<Integer, Integer>(2, 0.75f);
public static void main(String[] args) throws InterruptedException {
map.put(5, 55);
new Thread("Thread1") {
public void run() {
map.put(7, 77);
System.out.println(map);
};
}.start();
new Thread("Thread2") {
public void run() {
map.put(3, 33);
System.out.println(map);
};
}.start();
}
}
这个方法的目的是将原链表数据的数组拷到新的链表数组中,拷贝过程中如果形成环链的呢?下面用一个简单的例子来说明一下:
public class InfiniteLoop {
static final Map<Integer, Integer> map = new HashMap<Integer, Integer>(2, 0.75f);
public static void main(String[] args) throws InterruptedException {
map.put(5, 55);
new Thread("Thread1") {
public void run() {
map.put(7, 77);
System.out.println(map);
};
}.start();
new Thread("Thread2") {
public void run() {
map.put(3, 33);
System.out.println(map);
};
}.start();
}
}
下面通过debug跟踪调试来看看如果导致HashMap形成环链,断点位置:
- 线程1的put操作
- 线程2的put操作
- 线程2的输出操作
HashMap源码transfer方法中的第一行、第六行、第九行
测试开始
1.使线程1进入transfer方法第一行,此时map的结构如下
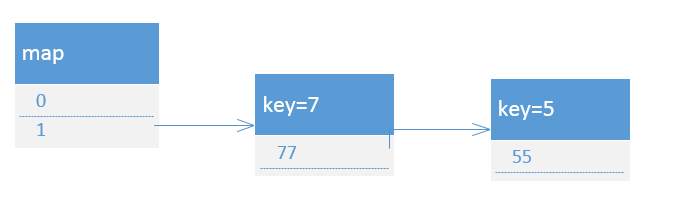
2.使线程2进入transfer方法第一行,此时map的结构如下:
3.接着切换回线程1,执行到transfer的第六行,此时map的结构如下:
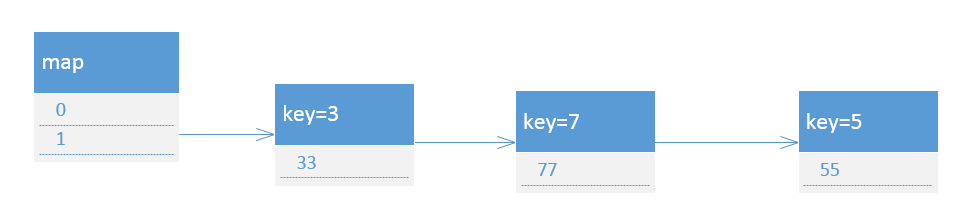
4.然后切换回线程2使其执行到transfer方法的第六行,此时map的结够如上
5.接着切换回线程1使其执行到transfer方法的第九行,然后切换回线程2使其执行完,此时map的结构如下:
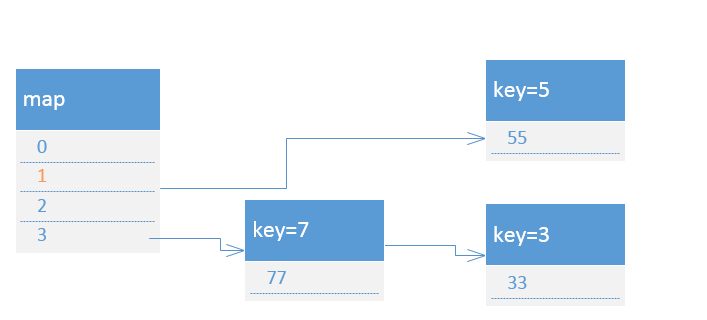
6.切换回线程1执行循环,因为线程1之前是停在HashMap的transfer方法的第九行处,所以此时transfer方法的节点e的key=3,e.next的key=7
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity); //线程1等线程2执行结束后
//从此处开始执行
//此时e的key=3,e.next.key=7
//但是此时的e.next.next的key=3了
//(被线程2修改了)
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
下面线程1开始执行第一次循环,循环后的map结构如下:
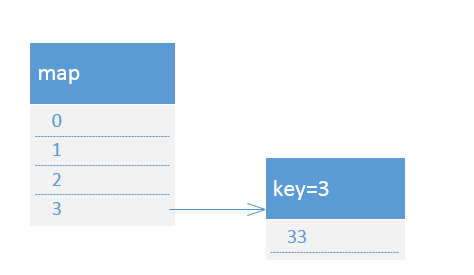
接着执行第二次循环:e.key=7,e.next.key=3,e.next.next=null
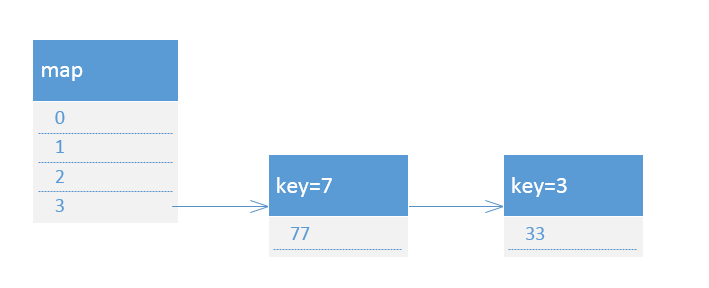
接着执行第三次循环,从而导致环链形成,map结构如下:
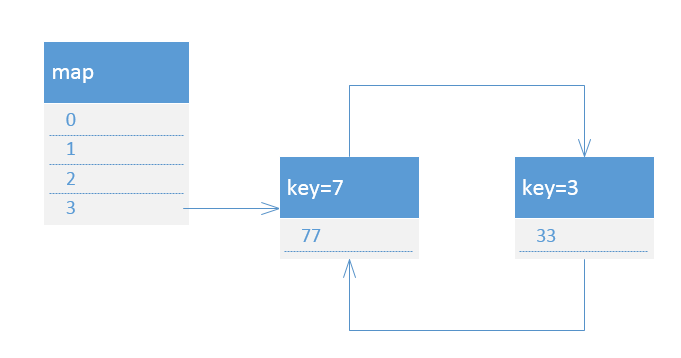
并且此时的map中还丢失了key=5的节点